ALTQ/CBQ Performance
Test Date: 97/08/15
Test System Configuration
The following measurements were done with three PentiumPro machines
(all 200MHz with 440FX chipset) running FreeBSD-2.2.2/altq-0.3.2.
Host A is a source, host B is a router, and host C is a sink.
CBQ is enabled only on the interface of host B connected to host C.
The link between host A and host B is 155Mbps ATM. The link between
host B and Host C is either 155M ATM, 10baseT, or 100based.
When 10baseT is used, a dumn hub is inserted. When 100baseT is used,
a direct connection is made by a cross cable, and the interfaces are set
to the full-duplex mode.
Efficient Network Inc. ENI-155p cards are used for ATM, Intel EtherExpress
Pro/100B cards are used for 10baseT and 100baseT.
Most of the tests use the TCP test mode of Netperf benchmark program.
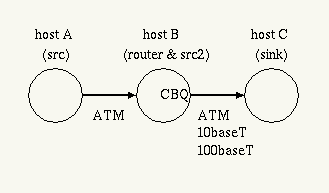
Figure 1
Throughput Overhead
Table 1 shows throughputs with CBQ on/off by TCP over different link type.
CBQ has three classes, and there is no other background traffic.
No overhead incured by CBQ can be observed, because the CBQ packet
processing can overlap the sending time of the previous packet.
Table 1. Throughput over Different Data Link
| device | cbq off
(Mbps) | cbq on
(Mbps) |
| ATM | 133.20 | 133.31 |
| 10baseT | 6.39 | 6.46 |
| 100baseT | 93.04 | 92.89 |
| local loop | 326.58 | 302.30 |
Latency Overhead
Table 2 and 3 show the CBQ overhead in latency for ATM and 10baseT.
In this test, request/reply style transactions are performed by UDP,
and the test measures how many transactions can be performed per
second. The rightmost column shows the average roundtrip time.
From the table, the overhead per packet is about 10 micro seconds.
Table 2. Latency over ATM
| CBQ | request
(bytes) | reply
(bytes) | trans.
per sec | RTT
(usec) |
| off | 1 | 1 | 2821.89 | 354 |
| on | 1 | 1 | 2744.03 | 364 |
| off | 64 | 64 | 2301.06 | 435 |
| on | 64 | 64 | 2243.14 | 446 |
| off | 1024 | 64 | 1476.31 | 677 |
| on | 1024 | 64 | 1454.39 | 688 |
| off | 8192 | 64 | 349.59 | 2534 |
| on | 8192 | 64 | 392.76 | 2546 |
Table 3. Latency over 10baseT
| CBQ | request
(bytes) | reply
(bytes) | trans.
per sec | RTT
(usec) |
| off | 1 | 1 | 2277.37 | 439 |
| on | 1 | 1 | 2234.13 | 448 |
| off | 64 | 64 | 1800.75 | 555 |
| on | 64 | 64 | 1768.02 | 566 |
| off | 1024 | 64 | 681.05 | 1468 |
| on | 1024 | 64 | 676.45 | 1478 |
| off | 8192 | 64 | 116.64 | 8573 |
| on | 8192 | 64 | 116.67 | 8571 |
Bandwidth Allocation
Figure 2 shows the bandwidth allocation performance.
TCP throughputs are measured when a class is allocated from 5%
to 95% of the link bandwidth.
The plot of the 10baseT case is scaled by 10 to be put in the same
graph.
The plots with "-FIFO" show the throughputs of the original queueing
(CBQ disabled).
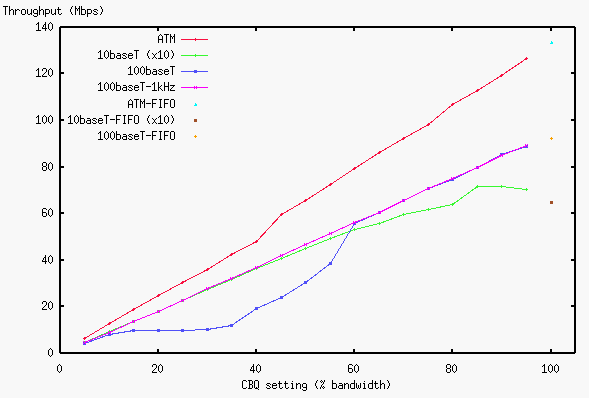
Figure 2
As can be seen from the graph, the allocated bandwidth changes
linearly for ATM and 10baseT, but not so well for 100baseT.
The problem of the 100baseT case is caused by the timer granularity.
Most Unix systems use 10 msec timer as default, and CBQ uses 20 msec
as the minimum timer since 1 tick can be arbitrarily short.
In CBQ, a class can send at most "maxburst" back-to-back packets.
If a class sends "maxburst" back-to-back packets at the beginning of a
20 msec cycle, the class gets suspended and would not be resumed until
the next timer event, unless other event trigger occurs.
If this situation continues, the transfer rate becomes
rate = packetsize * maxburst * 8 / 0.02
Now, assume maxburst is 16 (default) and the packet size is MTU.
For Ethernet whose MTU is 1500 bytes, the calculated rate is 9.6Mbps.
For ATM whose MTU is 9180 bytes, the calculated rate is 58.8Mbps.
This makes it difficult to handle 100Mbps 100baseT whose MTU is
small (1500) compared with its bandwidth.
To back up this theory, I tested the performance of the kernel whose
timer granularity is modified to 1kHz, plotted as "100baseT-1kHz".
With this kernel, the calculated rate becomes 96Mbps.
Depending solely on the kernel timer, however, is the worst case.
In more realistic settings, there are other flows that can trigger CBQ
to calibrate sending rates.
Also, TCP's ACK can be a good trigger since TCP receives an ACK every
two packets when in the steady state. This is the reason the ATM case
scales beyond 58.8Mbps.
Bandwidth Guarantee
Figure 3 shows the bandwidth guarantee performance.
Four classes, allocated 10Mbps, 20Mbps, 30Mbps and 40Mbps, are
defined.
A TCP flow matching the default class is sent during the test period.
Four flows each corresponding to the defined classes start with 5
second delay.
To avoid oscillation by process scheduling, class-0 and class-2 are
sent from host B and the other three classes are sent from host A.
The cbqprobe tool included in the altq release is used to get the CBQ
statistics every 400 msec, and the cbqmonitor tool also included in
the release is used to make the graph.
As can be seen from the graph, each class gets its share and there's
no effect from other traffic. Also note that the background flow gets
the remaining bandwidth.
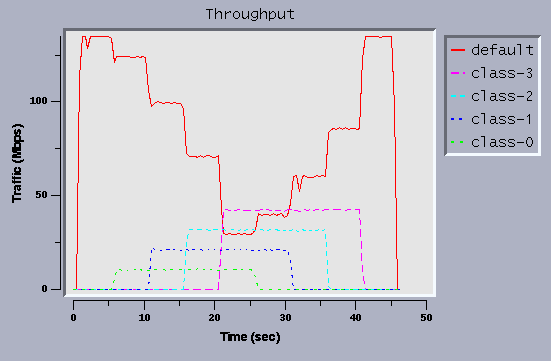
Figure 3
Figure 4 shows the trace that running the same scenario with CBQ disabled.
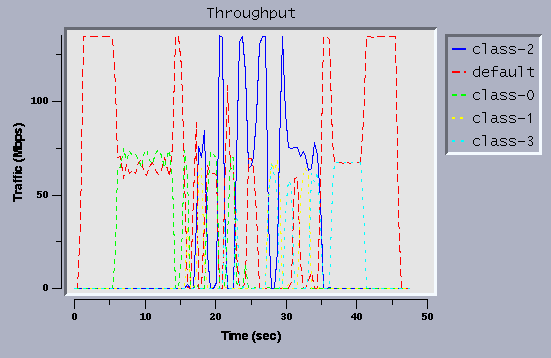
Figure 4
Link Sharing by Borrowing
Link Sharing Configuration
The setting is similar to the two agency setting used by Sally Floyd
in her papers.
The class hierarchy is defined as in Figure 4.

Figure 5
Four TCP flows are generated as in Figure 5.
Agency X is emulated by host B and agency Y is emulated by host A.
Each TCP tries to send at its maximum rate and has some idle period.
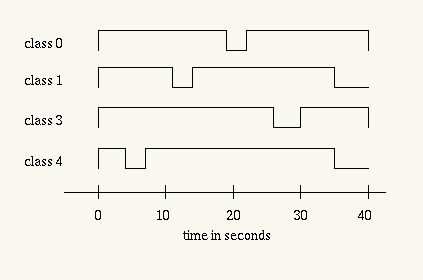
Figure 6
Traffic Trace
Figure 7 is generated by the same way described for Figure 3.
Both agencies get their share most of the time, but high
priority class-4 gets more than its share in some situations.
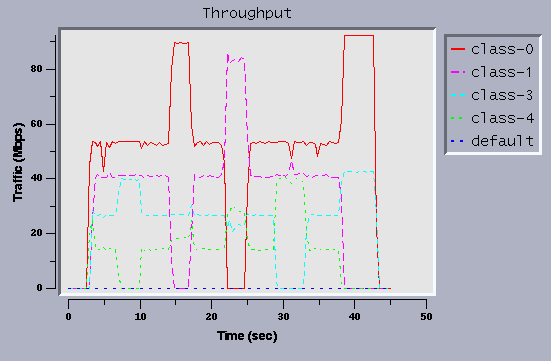
Figure 7
Figure 8 shows the trace where all the classes are set to the same priority.
Now, the problem of class-4 is improved.
The combination of priority and borrowing seems to need some refinement.
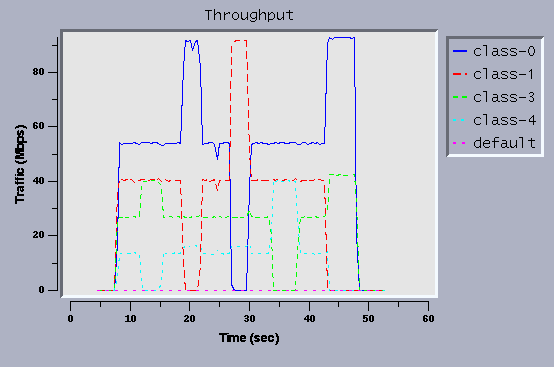
Figure 8
Figure 9 shows the trace that running the same scenario with CBQ disabled.
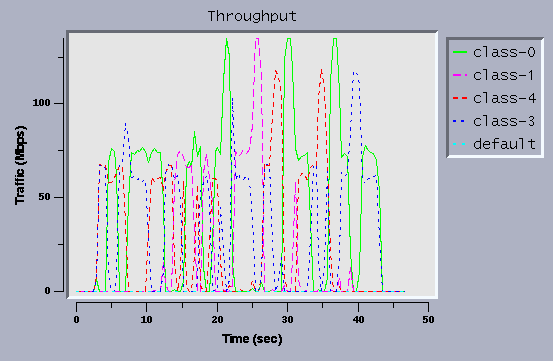
Figure 9
Back to ALTQ/CBQ page
Back to my home page